Pillters: Search & Filter Design for TSM
A filter system that directly unblocked multi-million dollar enterprise contracts. Three teams adopted it without redesign. The work wasn't the filter design — it was moving a sales pipeline.
The existing tooling was a single unstructured text field with no filter capability. Enterprise sales were flagging it as a blocker: customers with thousands of services couldn't manage their inventory without CLI workarounds.
A full system: a layered information architecture separating keyword search from structured filter rules from pagination, a composable rule builder with AND/OR logic and exclusion operators, and multiple search bar variants scaled to different query complexity levels.
The filter capabilities directly unblocked multi-million dollar enterprise contract deals. The pattern was adopted by Aria and Tanzu Application Platform without redesign.
Filter design looks contained until you account for the correctness requirements.
TSM's inventory datagrid was the surface platform engineers spent most of their time in, scanning, managing, and cross-referencing services across clusters. At enterprise scale, that meant thousands of services per project.
The original architecture loaded all service data into the frontend. That worked at small scale, but customers were projecting inventories in the thousands, and loading that volume into the browser caused prohibitive latency. The data moved to the backend and was accessed via API.
That created a harder problem. Microservices are dynamic: they come and go constantly. Because their position in the database wasn't stable between calls, consistent pagination wasn't reliable. A user looking for services starting with M had no practical way to get there without clicking through pages that might not represent the same dataset they started with. Calling thousands of backend services also introduced its own latency on every query.
Filters were the answer. If users could define what they wanted to see before the data came back, the dataset narrowed at the source. The UI problem and the technical problem had the same solution: let users slice the inventory upfront. Enterprise sales were already flagging the missing capability as a contract blocker.
 The filter rule builder — AND/OR logic, field operators, and exclusion rules
The filter rule builder — AND/OR logic, field operators, and exclusion rules
I started by auditing the Clarity design system's base datagrid, understanding what the component model gave us and where it stopped. The gap wasn't just coverage; it was conceptual. Clarity's datagrid assumed users knew what they were looking for. TSM users at enterprise scale were navigating. They needed to narrow a large set to a manageable one, often without a specific target in mind. That's a different interaction model than search.
 Clarity datagrid audit — mapping what the component gave us and where it stopped
Clarity datagrid audit — mapping what the component gave us and where it stopped
 When-to-use matrix — search vs. filter vs. pagination decision framework
When-to-use matrix — search vs. filter vs. pagination decision framework
The core distinction: keyword search is fast and tolerant, for users who know what they want. Filter rules are structured and composable, for users who need to carve out a subset by property. Pagination sits underneath both. It's infrastructure, not interaction. Getting the IA right meant treating these as three separate concerns with a shared visual language, not one "search and filter" blob.
Clarity Datagrid Audit
The Clarity datagrid gave us a solid base: rows, columns, selection, sorting. What it didn't give us was any opinionated answer to filtering. I mapped exactly where the component stopped and where custom work had to start. This framing mattered: it kept us from reinventing things Clarity already did well, and clearly scoped what was actually our problem to solve.
Information Architecture
I defined the three-layer IA: keyword search (fast, tolerant, lives in the bar), structured filter rules (precise, composable, lives in a panel), and pagination (infrastructure, consistent behavior across both modes). The mistake to avoid was treating these as one feature. They have different mental models, different error states, and different feedback loops. Separating them in the IA meant each could be designed correctly.
Search Bar Variations
I designed multiple search bar variants across a spectrum of query complexity, from simple string match to multi-field, type-aware search. The tension: a more capable search bar is also a more intimidating one. The variants tested whether users parsed structured syntax (they didn't, reliably) versus visual affordances like field labels and chips (they did). That finding drove the final approach: progressive complexity, never raw syntax.
 Simple search bar — fast string match, low cognitive load
Simple search bar — fast string match, low cognitive load
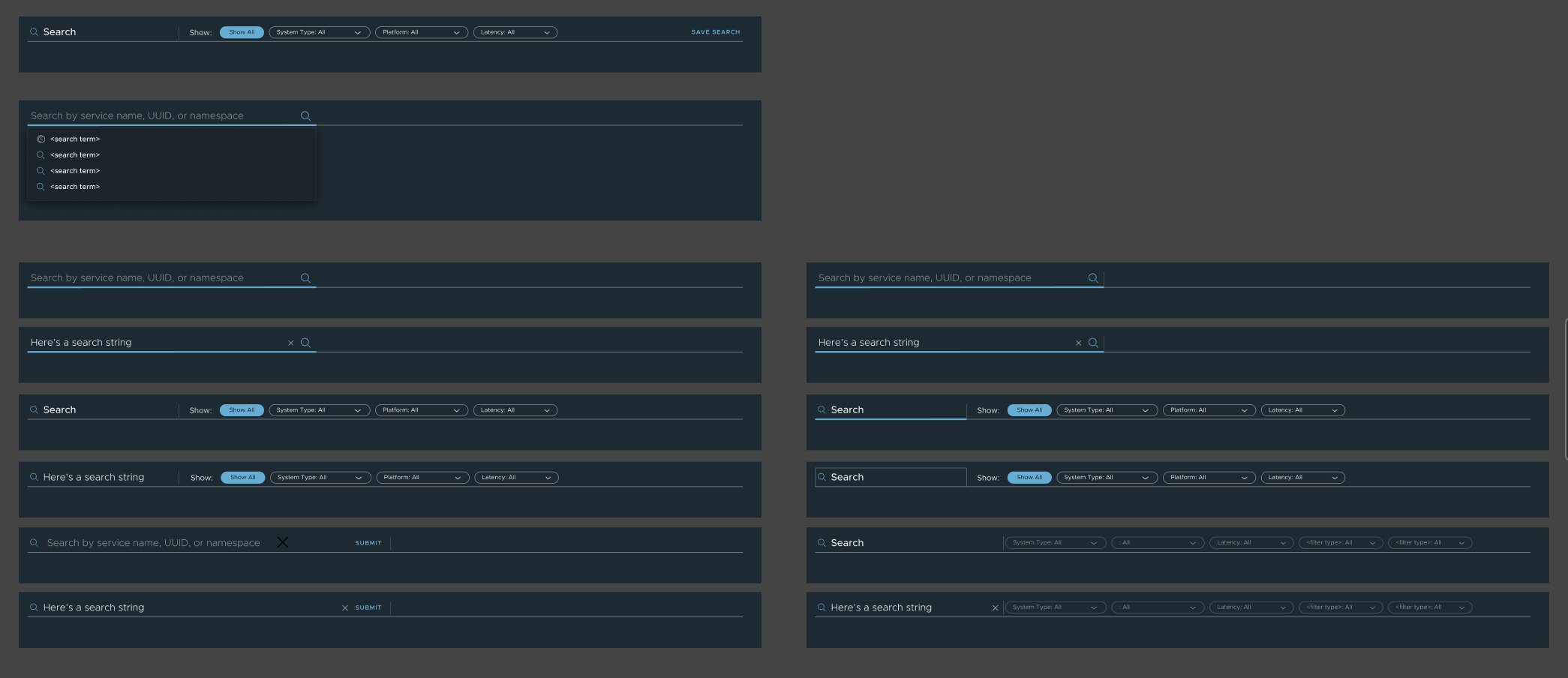 Advanced variants — field labels and chips over raw syntax
Advanced variants — field labels and chips over raw syntax
Filter Rule Architecture
The filter rule builder was the hardest piece. The interaction space is combinatorial: field + operator + value, combined with AND/OR logic, with the ability to exclude rather than just include. I advocated specifically for exclusion operators ("is not", "does not exist"), because include-only rules force users to enumerate every valid option. With exclusions, you describe the exception, not the exhaustive list. The rule preview closed the feedback loop: before committing, users could see which rows their rules would match. This same pattern was later used in Availability Targets for Spaces.
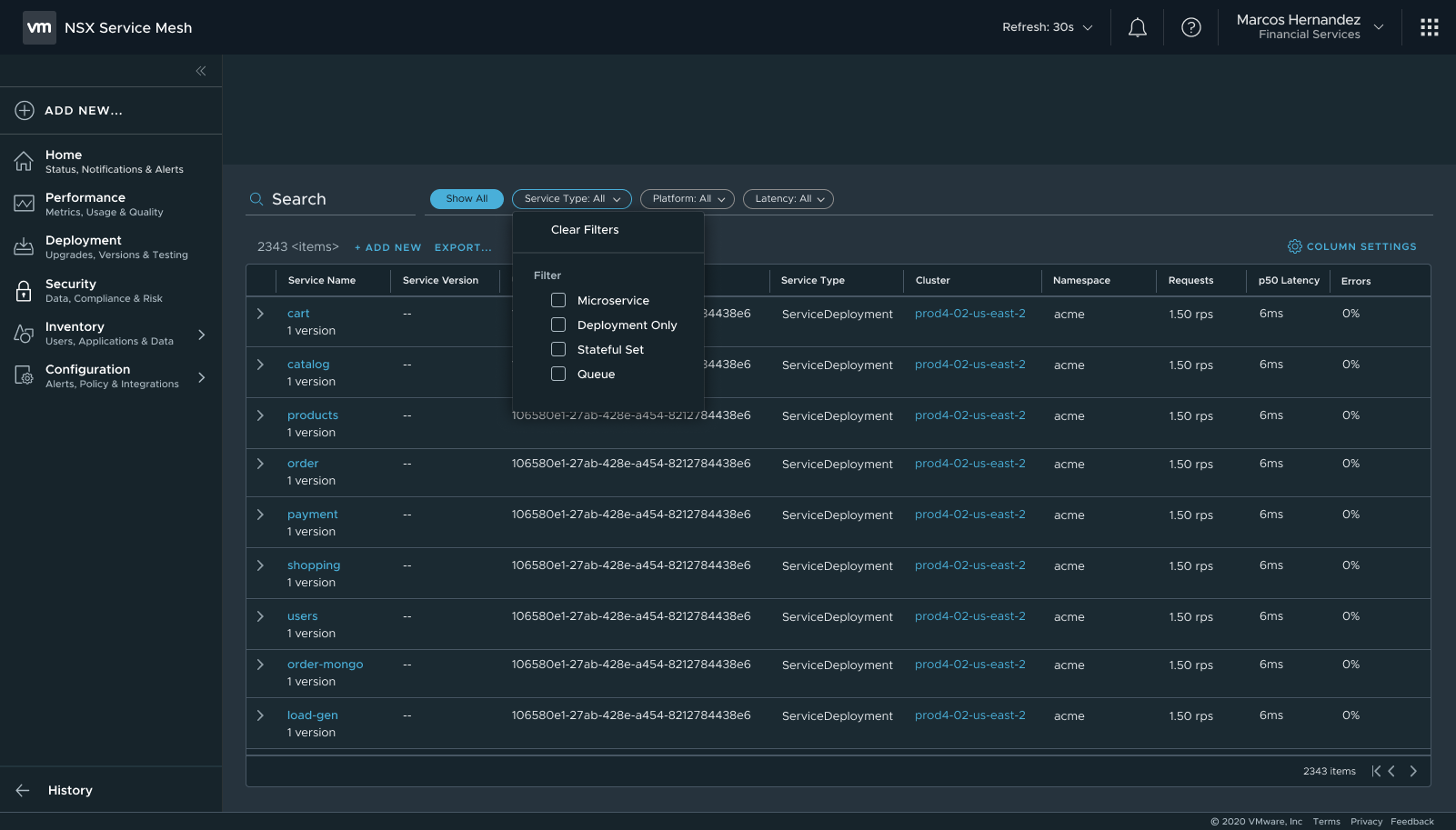 Filter panel open — field, operator, and value inputs with AND/OR toggle
Filter panel open — field, operator, and value inputs with AND/OR toggle
Pagination
Pagination couldn't be the primary solution for a dataset this dynamic. When microservice positions in the database shift between API calls, page numbers become unreliable. The dataset a user was on page 3 of might not be the same dataset when they hit page 4. Filters had to come first. Once a user had defined what they wanted to see, pagination of that filtered subset was predictable and stable.
The remaining design work was explicit behavior at the intersection of filter state and pagination state: what happens to your page position when you add a filter, remove one, or clear all. Those aren't UX preferences. They're correctness requirements.
Aria Partnership & Fleet DS
The Pillters system was adopted by Aria (VMware's observability platform) and later by Tanzu Application Platform and Fleet DS. Each adoption required adapting the pattern to a different product context: different data densities, different user roles, different framework constraints (Angular vs React). The underlying IA held across all of them.
 Design guidelines documentation — shipped to enable Aria and Fleet DS adoption without rework
Design guidelines documentation — shipped to enable Aria and Fleet DS adoption without rework
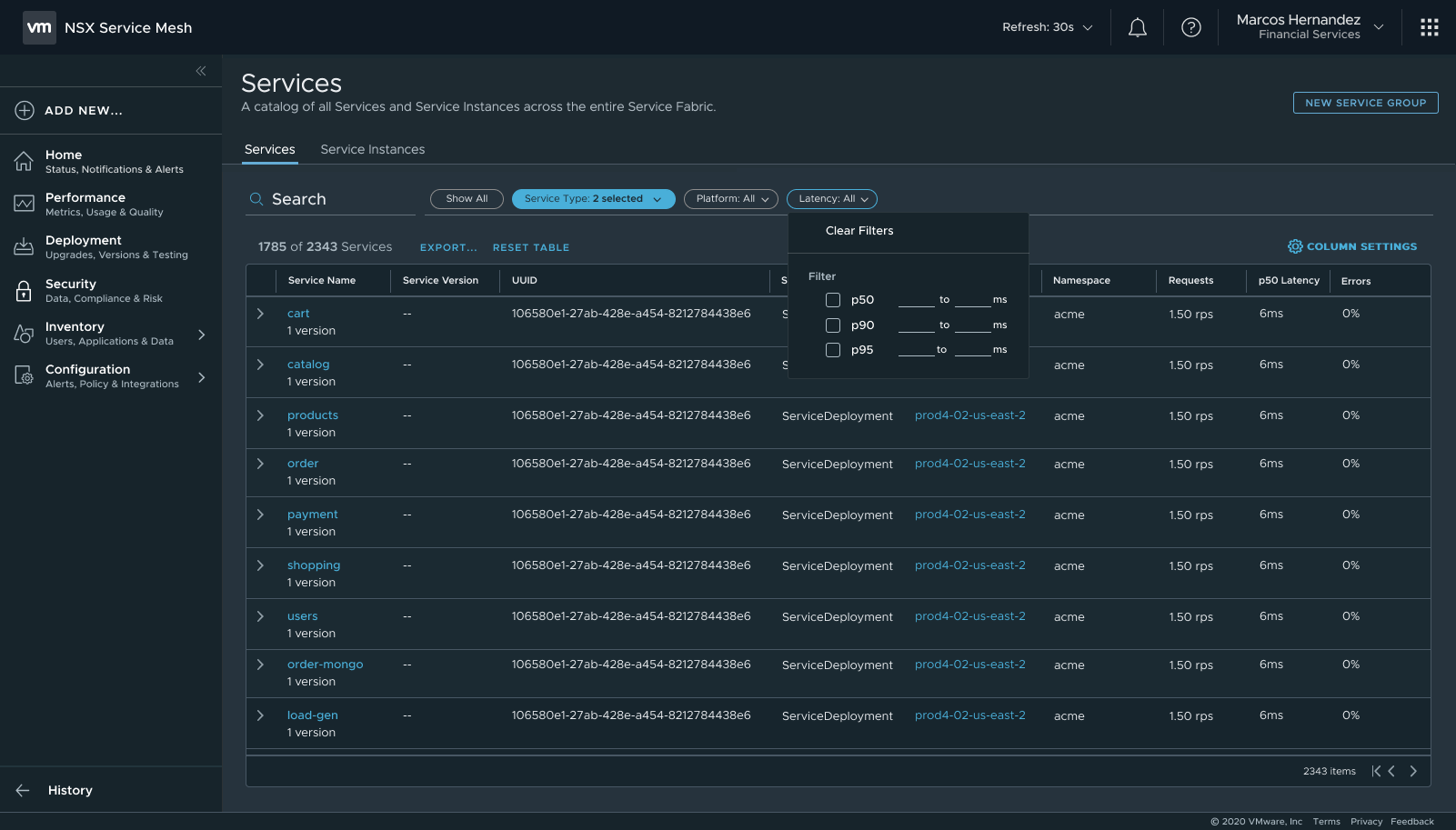
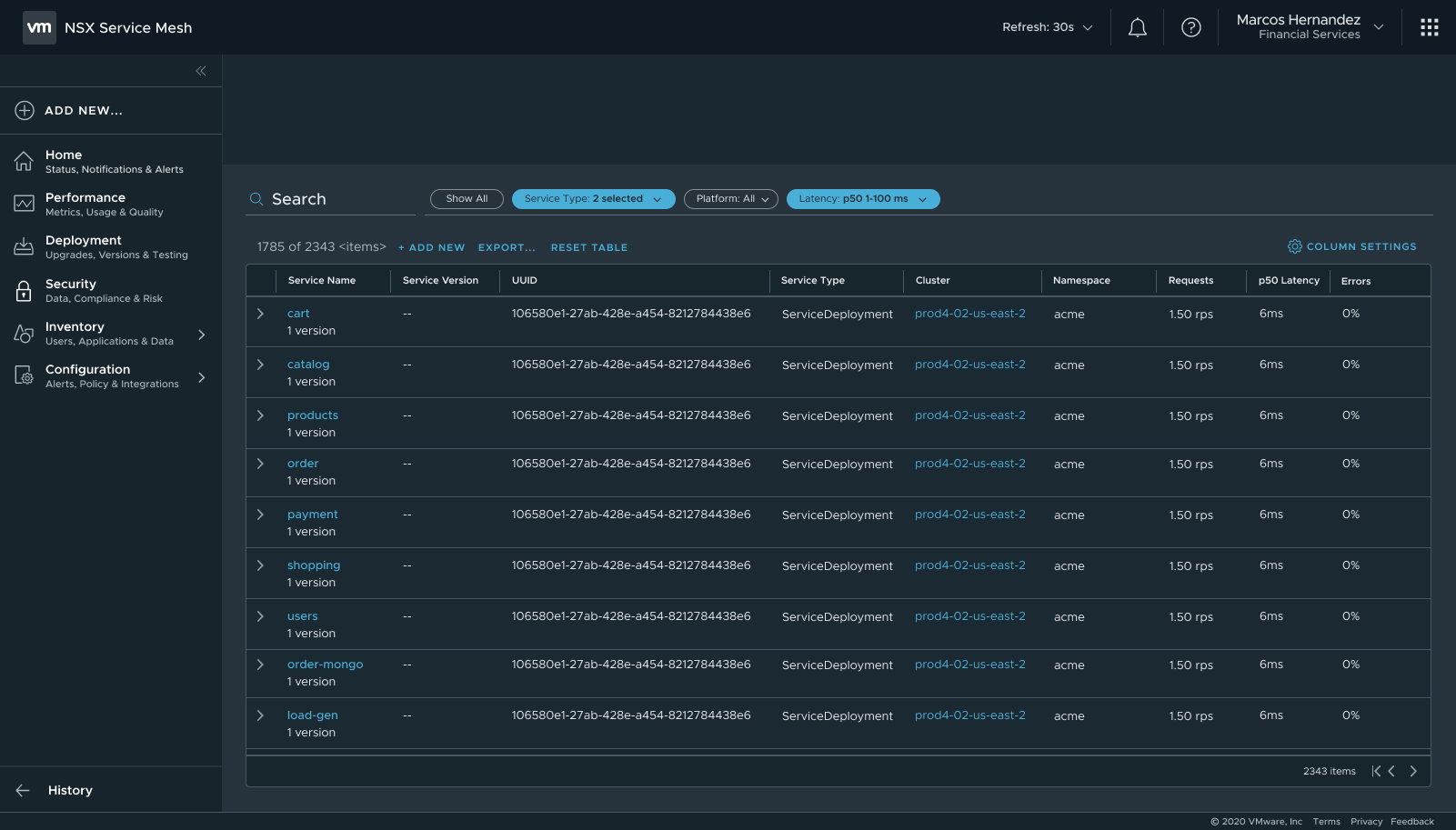 Filters applied — active filter chips, result count, clear all action
Filters applied — active filter chips, result count, clear all action
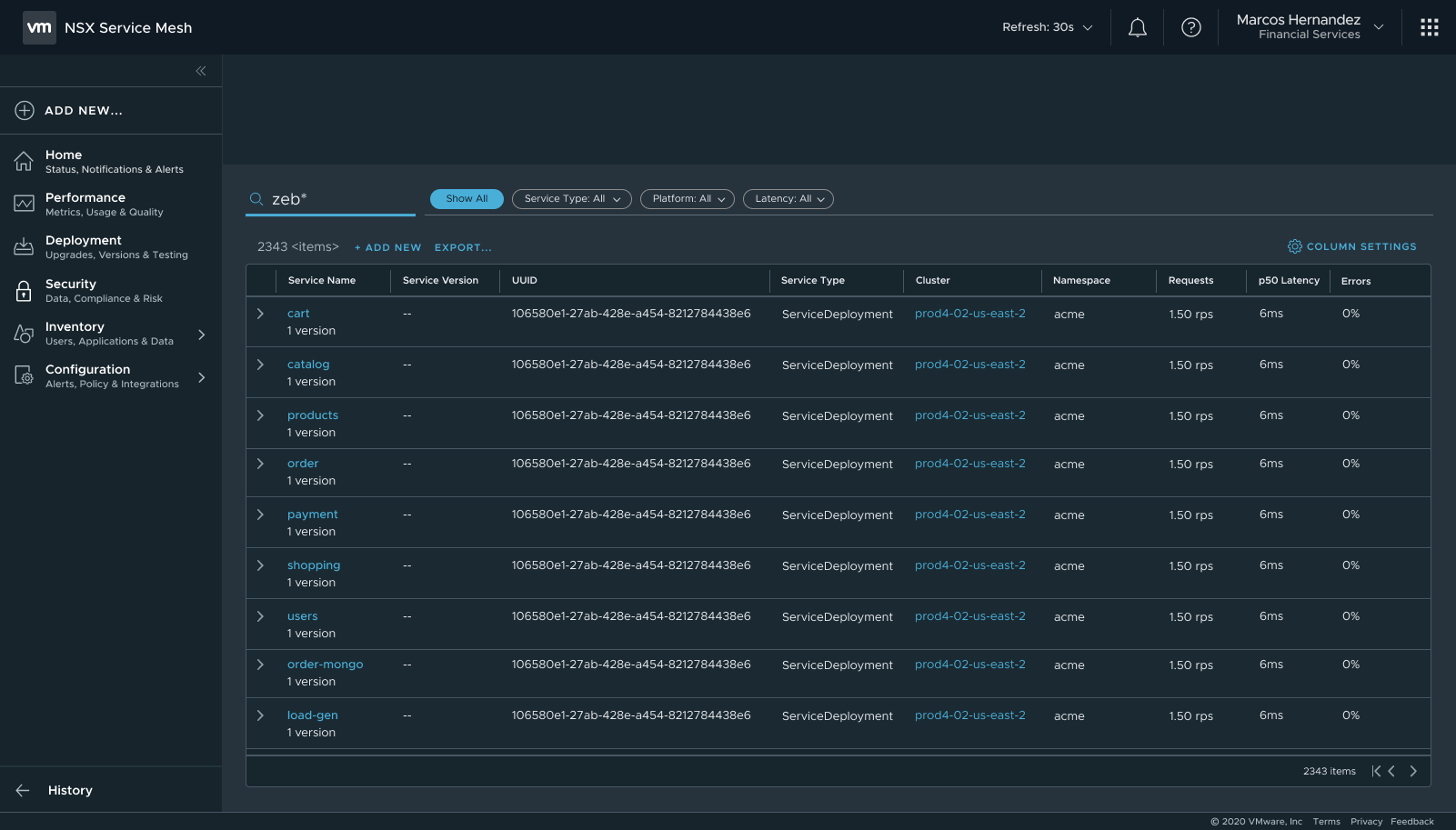
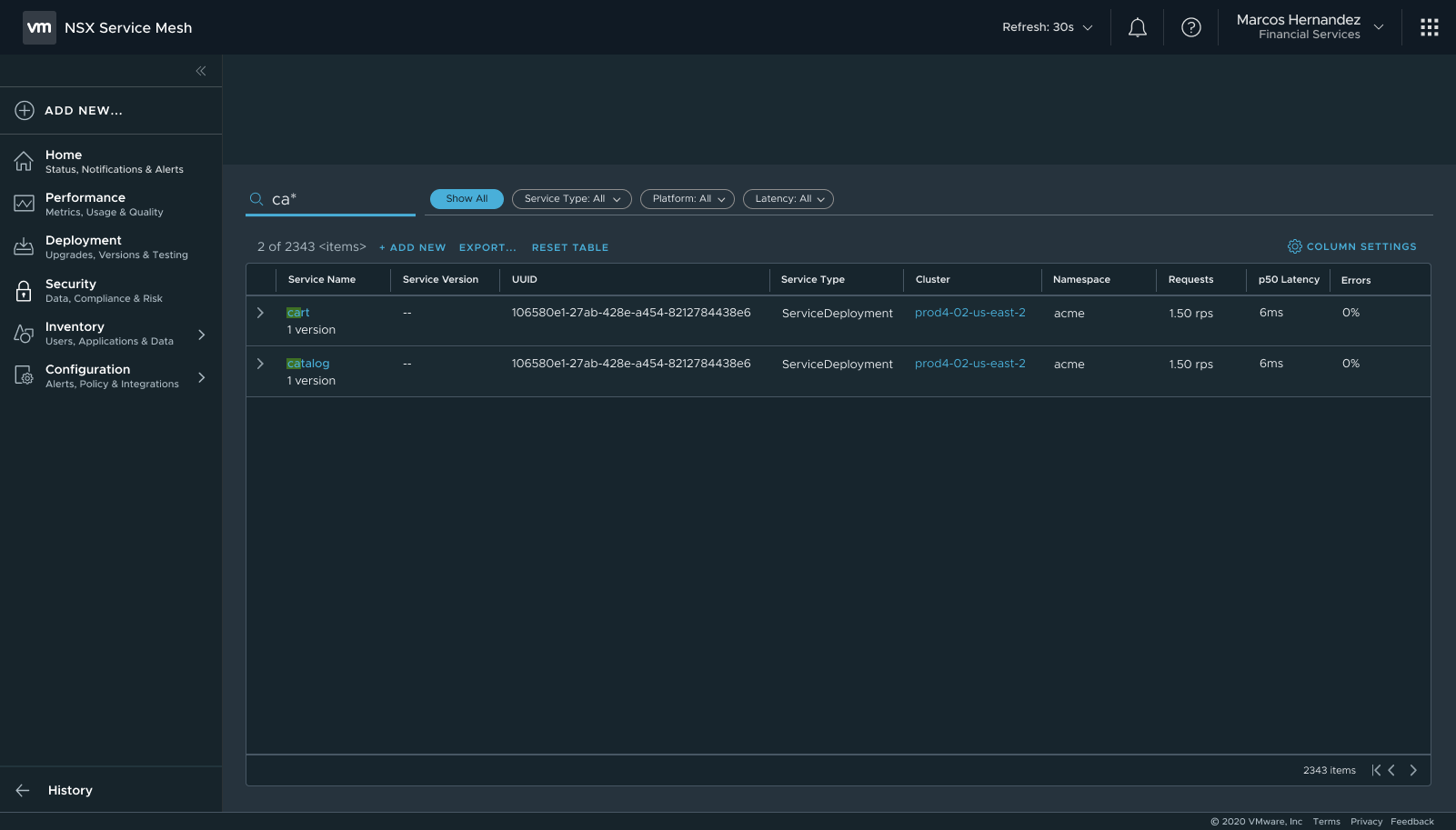 Matches found — filtered results with pagination state preserved
Matches found — filtered results with pagination state preserved
I wish I'd documented the IA decisions more formally while making them. The pattern got adopted across three platforms largely because I was there to explain it. A stronger spec would have meant the rationale traveled without me.
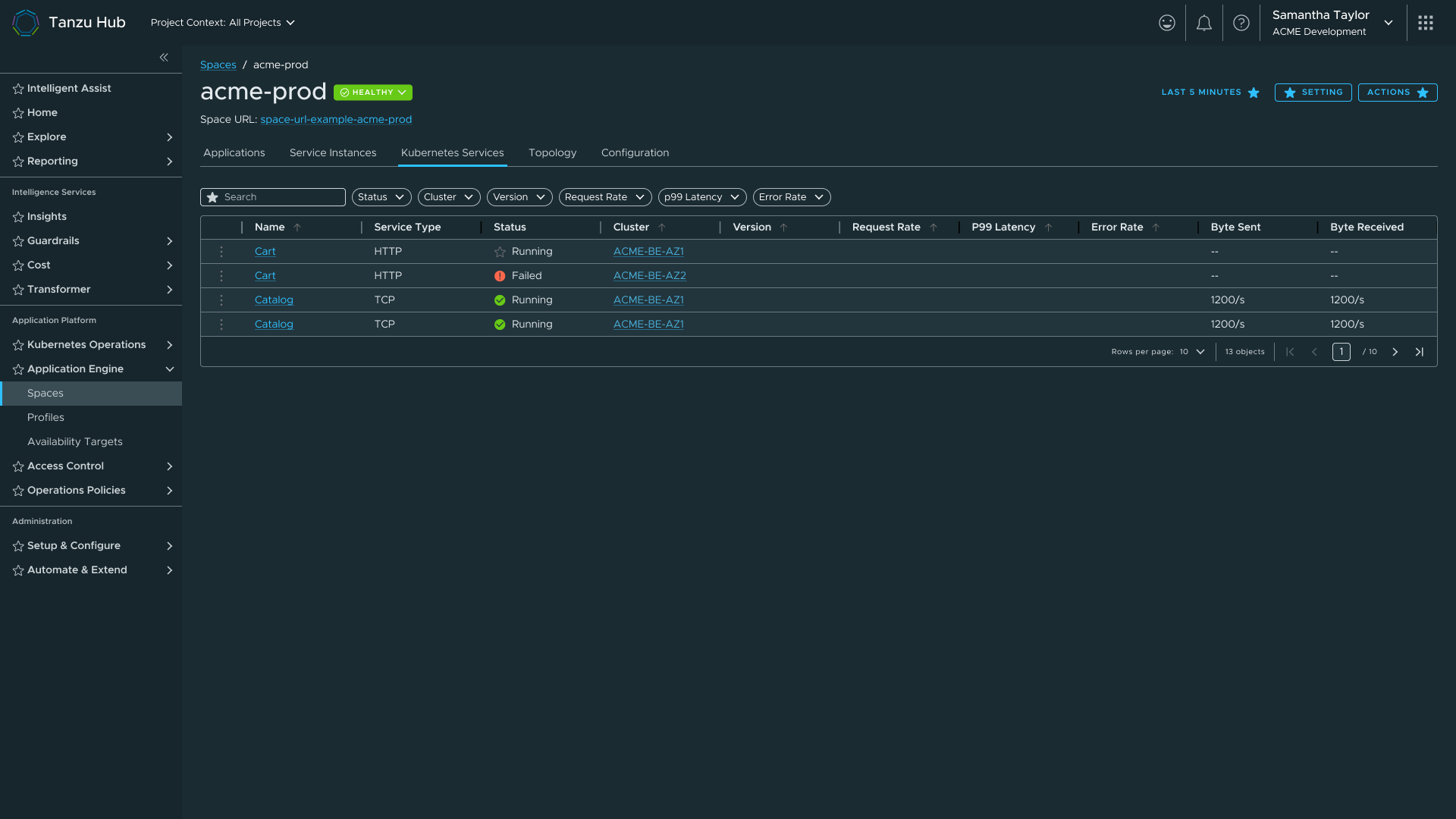 Pillters in Tanzu Hub — the same IA pattern, adapted to a different product context without rework
Pillters in Tanzu Hub — the same IA pattern, adapted to a different product context without rework